
权威AI测试MLPerf放榜,墨芯S30单卡算力超英伟达H100夺全球第一

9月9日,全球权威AI基准评测MLPerf Inference v2.1榜单公布结果。
MLPerf是业内公认的国际权威AI性能基准评测,由图灵奖得主大卫·帕特森(David Patterson)联合谷歌、英伟达 、英特尔、Facebook、浪潮等全球AI领军企业,以及来自哈佛大学、斯坦福大学等学术机构的研究人员创立。
该测评以其标准严格、测评严谨而著称,英伟达、高通等国际AI芯片企业均携最强产品参加测评,竞争十分激烈,各赛道均有数百项产品提交成绩。
中国AI芯片企业首次超越英伟达“史上最强GPU”、未来4nm产品——H100:中国AI芯片明星创业公司——墨芯人工智能(以下简称“墨芯”)S30计算卡以95784 FPS的单卡算力,夺得Resnet-50模型算力全球第一。
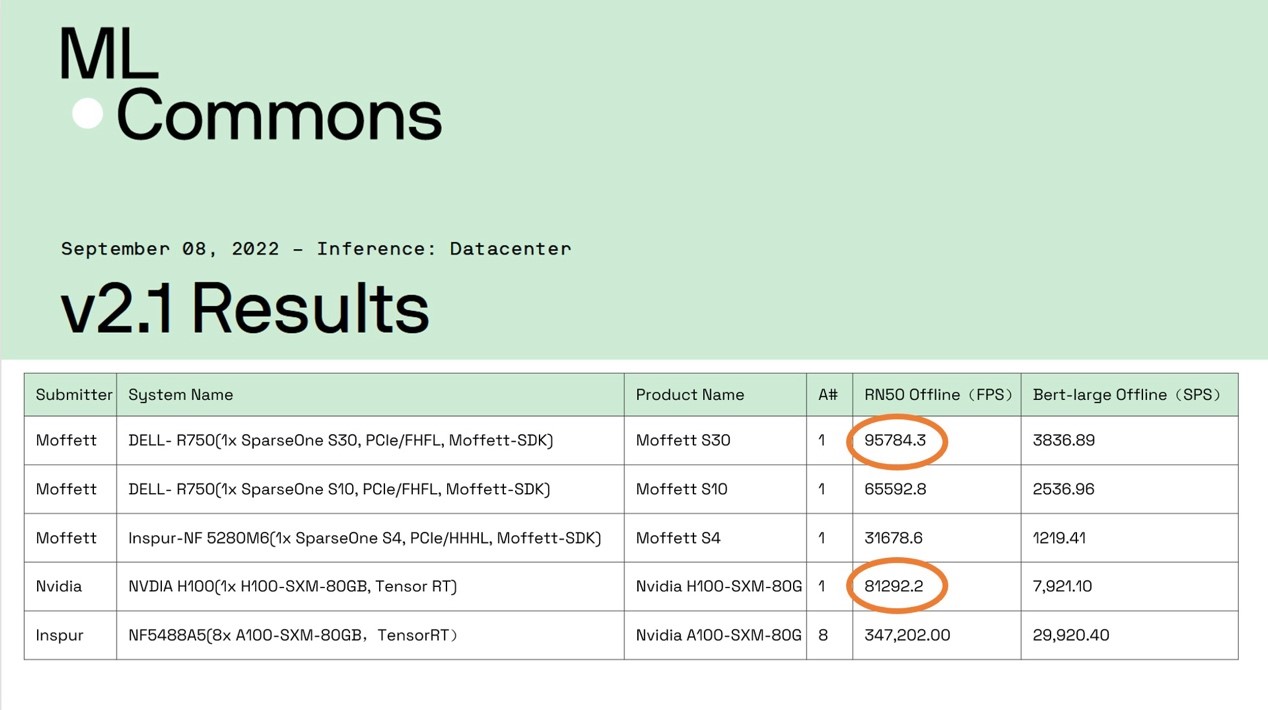 以上数据摘自MLCommons官网MLPerf Inference v2.1测试结果
以上数据摘自MLCommons官网MLPerf Inference v2.1测试结果墨芯首次参赛 单卡算力全球第一
众所周知,“单卡算力”是检验AI计算产品的“真标准”。
墨芯夺冠项目是数据中心最常用主流模型ResNet-50,该赛道竞争尤为激烈,竞争者包括H100、A100。
S30以ResNet-50 95784 FPS的单卡算力夺得第一,是英伟达未来4nm产品——H100的1.2倍,是A100的2倍。

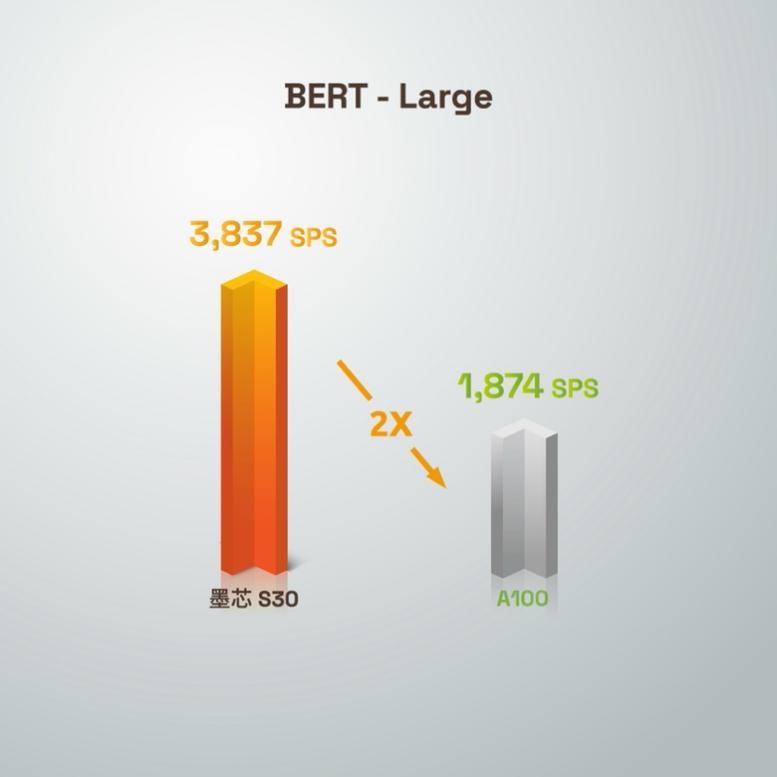
同时,墨芯S30运行BERT-Large是A100的2倍,仅次于H100,在Bert-large高精度模型(99.9%),单卡算力达3,837 SPS。
值得强调的是此次是“12nm”战胜“4nm”。

从竞争者角度看,墨芯参与的ResNet-50和BERT-Large都是数据中心最常用主流模型,因此竞争尤为激烈。特别是竞争者包括H100,是英伟达迄今推出的最强大的GPU,据悉使用台积电最新的4纳米工艺,可谓“最强王者”。而战胜“最强王者”,足以体现墨芯S30采用12nm,性能已经站在世界顶尖水平。
精度要求99%以上,经受严格检验

更值得一提的是,MLPerf的测试要求非常严格:不仅考验各产品算力,同时设置精度要求在99%以上,主要为了考察AI推理精度的高要求对计算性能的影响。换句话说,参赛厂商无法以牺牲精度的方式换取算力提升,在这种严要求下夺冠,表明了墨芯的硬核技术实力。